| CONTENTS |
If you've been reading this book sequentially, you've read all about the core Java language constructs, including the object-oriented aspects of the language and the use of threads. Now it's time to shift gears and start talking about the Java Application Programming Interface (API), the collection of classes that comprise the standard Java packages and come with every Java implementation. Java's core packages are one of its most distinguishing features. Many other object-oriented languages have similar features, but none has as extensive a set of standardized APIs and tools as Java does. This is both a reflection of and a reason for Java's success. Table 9-1 lists the most important packages in the API and shows which chapters discuss each of the packages.
|
Package |
Contents |
Chapter |
|---|---|---|
java.applet |
The Applet API |
22 |
java.beans |
JavaBeans API |
21 |
|
java.io, java.nio |
Input and output |
11 |
|
java.lang, java.lang.ref |
Basic language classes |
4, 5, 6, 7, 8, 9 |
java.lang.reflect |
Reflection |
7 |
|
java.net, java.rmi |
Networking and Remote Method Invocation classes |
12 |
|
java.text, java.util.regex |
International text classes and regular expressions |
9 |
java.util |
Utilities and collections classes |
9, 10, 11 |
|
javax.swing, java.awt |
Swing GUI and 2D graphics |
15, 16, 17, 18, 19 |
As you can see in Table 9-1, we examined some classes in java.lang in earlier chapters on the core language constructs. Starting with this chapter, we throw open the Java toolbox and begin examining the rest of the API classes, starting with text-related utilities, because they are fundamental to all kinds of applications.
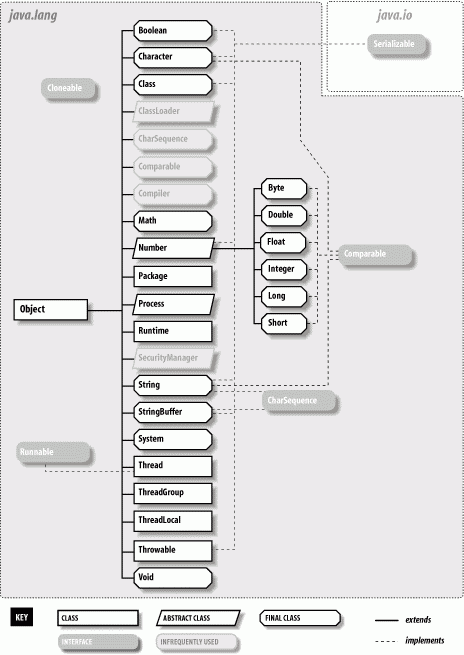
We begin our exploration with some of the fundamental language classes in java.lang concerning strings. Figure 9-1 shows the class hierarchy of the java.lang package.
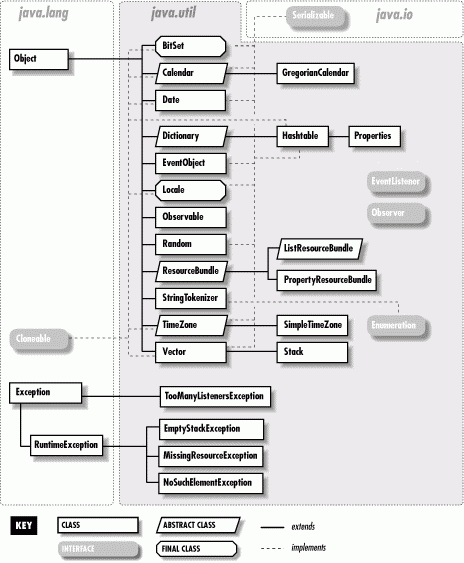
We'll also look at some of the classes in java.util in this chapter, including locales for internationalization. We'll cover more classes in java.util, including classes that support math, date and time values, collections, and many more in Chapter 10. Figure 9-2 shows the class hierarchy of the java.util package.
In this chapter, we cover most of the special-purpose, text-related APIs in Java, including classes for simple parsing of words and numbers, text formatting, internationalization, and regular expressions. But since so much of what we do with computers is oriented around text, classifying some APIs as text-related can be somewhat arbitrary. Some of the text-related packages we cover in the next chapter include the Java Calendar API, the Properties and User Preferences APIs, and the Logging API. But probably the most important new tools in the text arena are those for working with the Extensible Markup Language, XML. In Chapter 23, we cover this topic in detail, along with the XSL/XSLT stylesheet language. Together they provide a powerful framework for rendering documents.
Now we take a closer look at the Java String class (or, more specifically, java.lang.String). Because strings are used so extensively, the Java String class has quite a bit of functionality. We'll test-drive most of the important features, but if you want to go deeper, you should refer to a Java class reference manual such as the Java Fundamental Classes Reference by Mark Grand and Jonathan Knudsen (O'Reilly).
A String object encapsulates a sequence of Unicode characters. Strings are immutable; once you create a String object, you can't change its value. Operations that appear to change the content or length of a string instead return a new String object that copies or internally references the needed characters of the original. Java implementations make an effort to consolidate identical strings and string literals in the same class into a shared-string pool.
Literal strings are allocated with double quotes and can be assigned to a String variable:
String quote = "To be or not to be";
Java automatically converts the literal string into a String object. If you're a C or C++ programmer, you may be wondering about the internal structure of this string; you don't have to worry about this with Java strings. We've said that the String class stores Unicode characters, and Java uses arrays internally to hold them. But the details are encapsulated in the String class, so you don't have to worry about them.
As always, arrays in Java are real objects that know their own length, so String objects in Java don't require special terminators. If you need to know the length of a String, use the length() method:
int length = quote.length( );
Strings can take advantage of the only overloaded operator in Java, the + operator, for string concatenation. The following code produces equivalent strings:
String name = "John " + "Smith";
String name = "John ".concat("Smith");
Literal strings can't span lines in Java source files, but we can concatenate lines to produce the same effect:
String poem =
"'Twas brillig, and the slithy toves\n" +
" Did gyre and gimble in the wabe:\n" +
"All mimsy were the borogoves,\n" +
" And the mome raths outgrabe.\n";
Embedding lengthy text in source code should now be a thing of the past, given that we can retrieve a String from anywhere on the planet via a URL. In Chapter 13, we'll see how to do things like this:
String poem = (String) new URL(
"http://myserver/~dodgson/jabberwocky.txt").getContent( );
In addition to making strings from literal expressions, you can construct a String from an array of characters:
char [] data = new char [] { 'L', 'e', 'm', 'm', 'i', 'n', 'g' };
String lemming = new String( data );
You can also construct a String from an array of bytes:
byte [] data = new byte [] { (byte)97, (byte)98, (byte)99 };
String abc = new String(data, "ISO8859_1");
The second argument to the String constructor for byte arrays is the name of an encoding scheme. The String construct uses it to convert the given bytes to Unicode characters. Unless you know something about Unicode, you can use the form of the constructor that accepts a byte array only; the default encoding scheme on your system will be used.[1]
Conversely, the charAt() method of the String class lets you access the characters of a String in an array-like fashion:
String s = "Newton";
for ( int i = 0; i < s.length( ); i++ )
System.out.println( s.charAt( i ) );
This code prints the characters of the string one at a time. Alternately, we can get the characters all at once with toCharArray(). Here's a way to save typing a bunch of single quotes:
char [] abcs = "abcdefghijklmnopqrstuvwxyz".toCharArray( );
We can get the string representation of most things with the static String.valueOf() method. Various overloaded versions of this method give us string values for all of the primitive types:
String one = String.valueOf( 1 ); String two = String.valueOf( 2.384f ); String notTrue = String.valueOf( false );
All objects in Java have a toString() method, inherited from the Object class. For class-type references, String.valueOf() invokes the object's toString() method to get its string representation. If the reference is null, the result is the literal string "null":
String date = String.valueOf( new Date( ) ); System.out.println( date ); // "Sun Dec 19 05:45:34 CST 2002" date = null; System.out.println( date ); // "null"
Because string concatenation uses the valueOf() method internally, it's common to use the empty string and the plus operator (+) to get the string value of any object. For example:
String two = "" + 2.384f; String today = "" + new Date( );
The standard equals() method can compare strings for equality; they contain exactly the same characters. You can use a different method, equalsIgnoreCase(), to check the equivalence of strings in a case-insensitive way:
String one = "FOO"; String two = "foo"; one.equals( two ); // false one.equalsIgnoreCase( two ); // true
A common mistake for novice programmers in Java is to compare strings with the == operator when they mean to use the equals() method. Remember that strings are objects in Java, and == tests for object identity, that is, whether the two arguments being tested are the same object. In Java, it's easy to make two strings that have the same characters but are not the same string object. For example:
String foo1 = "foo";
String foo2 = String.valueOf( new char [] { 'f', 'o', 'o' } );
foo1 == foo2 // false!
foo1.equals( foo2 ) // true
This mistake is particularly dangerous, because it often works for the common case in which you are comparing literal strings (strings declared with double quotes right in the code). The reason for this is that Java tries to manage strings efficiently by combining them. At compile time, Java finds all the identical strings within a given class and makes only one object for them. This is safe because strings are immutable and cannot change. You can coalesce strings in this way at runtime using the String intern() method. Interning a string returns an equivalent string reference that is unique across the VM.
The compareTo() method compares the lexical value of the String to another String, determining whether it sorts alphabetically earlier than, the same as, or later than the target string. It returns an integer that is less than, equal to, or greater than zero:
String abc = "abc"; String def = "def"; String num = "123"; if ( abc.compareTo( def ) < 0 ) // true if ( abc.compareTo( abc ) == 0 ) // true if ( abc.compareTo( num ) > 0 ) // true
On some systems, the behavior of lexical comparison is complex, and obscure alternative character sets exist. Java avoids this problem by comparing characters strictly by their position in the Unicode specification.
The java.text package provides a sophisticated set of classes for comparing strings, even in different languages. German, for example, has vowels with umlauts and another character that resembles the Greek letter beta and represents a double "s." How should we sort these? Although the rules for sorting such characters are precisely defined, you can't assume that the lexical comparison we used earlier has the correct meaning for languages other than English. Fortunately, the Collator class takes care of these complex sorting problems.
In the following example, we use a Collator designed to compare German strings. You can obtain a default Collator by calling the Collator.getInstance() method with no arguments. Once you have an appropriate Collator instance, you can use its compare() method, which returns values just like String's compareTo() method. The following code creates two strings for the German translations of "fun" and "later," using Unicode constants for these two special characters. It then compares them, using a Collator for the German locale;[2] the result is that "fun" (Spaß) sorts before "later" (später).
String fun = "Spa\u00df"; String later = "sp\u00e4ter"; Collator german = Collator.getInstance(Locale.GERMAN); if (german.compare(fun, later) < 0) // true
Using collators is essential if you're working with languages other than English. In Spanish, for example, "ll" and "ch" are treated as separate characters and alphabetized separately. A collator handles cases like these automatically.
The String class provides several simple methods for finding fixed substrings within a string. The startsWith() and endsWith() methods compare an argument string with the beginning and end of the String, respectively:
String url = "http://foo.bar.com/";
if ( url.startsWith("http:") ) // true
The indexOf() method searches for the first occurrence of a character or substring and returns the starting character position:
String abcs = "abcdefghijklmnopqrstuvwxyz"; int i = abcs.indexOf( 'p' ); // 15 int i = abcs.indexOf( "def" ); // 3
Similarly, lastIndexOf() searches for the last occurrence of a character or substring in a target string.
For more complex searching, you can use the new Regular Expression API, which allows you to look for and parse complex patterns. We'll talk about regular expressions later in this chapter.
A number of methods operate on the String and return a new String as a result. While this is useful, you should be aware that creating lots of strings in this manner can affect performance. If you need to modify a string often, you should use the StringBuffer class, as we'll discuss shortly.
trim() is a useful method that removes leading and trailing whitespace (i.e., carriage return, newline, and tab) from the String:
String str = " abc "; str = str.trim( ); // "abc"
In this example, we have thrown away the original String (with excess whitespace), so it will be garbage-collected.
The toUpperCase() and toLowerCase() methods return a new String of the appropriate case:
String down = "FOO".toLowerCase( ); // "foo" String up = down.toUpperCase( ); // "FOO"
substring() returns a specified range of characters. The starting index is inclusive; the ending is exclusive:
String abcs = "abcdefghijklmnopqrstuvwxyz"; String cde = abcs.substring(2, 5); // "cde"
As of Java 1.4, the String class adds two new methods that allow you to do pattern substitution: replaceAll() and replaceFirst(). We'll talk about these when we discuss regular expressions later in this chapter.
Many people complain when they discover that the Java String class is final (i.e., it can't be subclassed). There is a lot of functionality in String, and it would be nice to be able to modify its behavior directly. The String class is final because of performance and security implications. With final classes, the Java VM can make implementation-dependent optimizations, and since strings are used ubiquitously throughout the Java APIs, subclassing at the very least needs to be scrutinized carefully for security issues. Table 9-2 summarizes the methods provided by the String class.
|
Method |
Functionality |
|---|---|
|
charAt() |
Gets a particular character in the string |
|
compareTo() |
Compares the string with another string |
|
concat() |
Concatenates the string with another string |
|
copyValueOf() |
Returns a string equivalent to the specified character array |
|
endsWith() |
Checks whether the string ends with a specified suffix |
|
equals() |
Compares the string with another string |
|
equalsIgnoreCase() |
Compares the string with another string, ignoring case |
|
getBytes() |
Copies characters from the string into a byte array |
|
getChars() |
Copies characters from the string into a character array |
|
hashCode() |
Returns a hashcode for the string |
|
indexOf() |
Searches for the first occurrence of a character or substring in the string |
|
intern() |
Fetches a unique instance of the string from a global shared-string pool |
|
lastIndexOf() |
Searches for the last occurrence of a character or substring in a string |
|
length() |
Returns the length of the string |
|
regionMatches() |
Checks whether a region of the string matches the specified region of another string |
|
replace() |
Replaces all occurrences of a character in the string with another character |
|
startsWith() |
Checks whether the string starts with a specified prefix |
|
substring() |
Returns a substring from the string |
|
toCharArray() |
Returns the array of characters from the string |
|
toLowerCase() |
Converts the string to lowercase |
|
toString() |
Returns the string value of an object |
|
toUpperCase() |
Converts the string to uppercase |
|
trim() |
Removes leading and trailing whitespace from the string |
|
valueOf() |
Returns a string representation of a value |
|
matches() |
Determines if the whole string matches a regular expression pattern |
|
replaceFirst() |
Replaces the first occurrence of a regular expression pattern with a pattern |
|
replaceAll() |
Replaces all occurrences of a regular expression pattern with a pattern |
|
split() |
Splits the string into an array of strings using a regular expression pattern as a delimiter |
In contrast to the immutable string, the java.lang.StringBuffer class is a modifiable and expandable buffer for characters. It's an efficient alternative to code like this:
String ball = "Hello"; ball = ball + " there."; ball = ball + " How are you?";
This example repeatedly produces new String objects. The character array must be copied over and over, which can adversely affect performance. A more economical alternative is to use a StringBuffer object and its append() method:
StringBuffer ball = new StringBuffer("Hello");
ball.append(" there.");
ball.append(" How are you?");
The StringBuffer class provides a number of overloaded append() methods for appending any type of data to the buffer.
We can get a String back from the StringBuffer with its toString() method:
String message = ball.toString( );
You can also retrieve part of a StringBuffer, as a String, using one of the substring() methods.
StringBuffer also provides a number of overloaded insert() methods for inserting various types of data at a particular location in the string buffer. Furthermore, you can remove a single character or a range of characters with the deleteCharAt() and delete() methods. Finally, you can replace part of the StringBuffer with the contents of a String using the replace() method.
The String and StringBuffer classes cooperate so that even in this last operation, no copy of the data has to be made. The string data is shared between the objects, unless and until we try to change it in the StringBuffer.
You should use a StringBuffer instead of a String any time you need to keep adding characters to a string; it's designed to handle such modifications efficiently. You still have to convert the StringBuffer to a String when you need to use any of the methods in the String class, but you can print a StringBuffer directly using System.out.println() because println() calls the toString()method for you.
Another thing you should know about StringBuffer methods is that they are thread-safe (like most methods in the Java APIs). This means that multiple threads can work on the same StringBuffer instance, and modifications happen sequentially (without interfering).
You might be interested to know that the compiler uses a StringBuffer to implement String concatenation. Consider the following expression:
String foo = "To " + "be " + "or";
It is equivalent to:
String foo = new
StringBuffer( ).append("To ").append("be ").append("or").toString( );
A common programming task involves parsing a string of text into words or "tokens" that are separated by some set of delimiter characters. The java.util.StringTokenizer class is a utility that does just this. Before we go on, we should mention that in Java 1.4 the String class itself, in conjunction with the new regular expression package, has added string-tokenizing capabilities that are more powerful and convenient to use than the simple StringTokenizer. So we'll cover this topic again when we talk about splitting strings using the String split() method in the section of this chapter on regular expressions.
Let's look at an example using StringTokenizer. The following snippet reads words from the string text:
String text = "Now is the time for all good men (and women)...";
StringTokenizer st = new StringTokenizer( text );
while ( st.hasMoreTokens( ) ) {
String word = st.nextToken( );
...
}
First, we create a new StringTokenizer from the String. We invoke the hasMoreTokens() and nextToken() methods to loop over the words of the text. By default, the StringTokenizer class uses standard whitespace characters—carriage return, newline, and tab—as delimiters.
The StringTokenizer is an enumeration. It implements the java.util.Enumeration interface, which means that StringTokenizer also implements two more general methods for accessing elements: hasMoreElements() and nextElement(). These methods are defined by the Enumeration interface; they provide a standard way to return a sequence of values. The Enumeration interface is implemented by many items that return sequences or collections of objects. The advantage of nextToken() is that it returns a String, whereas nextElement() returns an Object type that must be cast. We'll talk about enumerations and iterators (another interface for the same concept) in the next chapter.
You can also specify your own set of delimiter characters in the StringTokenizer constructor, using another String argument to the constructor. Any contiguous combination of the specified characters that appears in the target string is treated as the equivalent of whitespace for tokenizing:
text = "http://foo.bar.com/";
tok = new StringTokenizer( text, "/:" );
if ( tok.countTokens( ) < 2 )
... // bad URL
String protocol = tok.nextToken( ); // "http"
String host = tok.nextToken( ); // "foo.bar.com"
This example parses a URL specification to get at the protocol and host components. The characters / and : are used as separators. The countTokens() method provides a fast way to see how many tokens will be returned by nextToken() without actually creating the String objects.
StringTokenizer can do a few more tricks. An overloaded form of nextToken() accepts a string that defines a new delimiter set for that and subsequent reads. The StringTokenizer constructor also accepts a flag that specifies that separator characters are to be returned individually as tokens themselves. By default, the delimiter characters are skipped over and not returned.
Again, we'll return to this topic when we talk about regular expressions and the String split() method later in this chapter.
Parsing and formatting text is a large and open-ended topic. So far in this chapter we've looked at only primitive operations on strings—creation, basic editing, searching, and simple tokenizing. Now we'd like to move on to more structured forms of text. Java has a rich set of APIs for parsing and printing formatted strings, including numbers, dates, times, and currency values. We'll cover most of these topics in this chapter, but we'll wait to discuss date and time formatting until Chapter 10.
In this section, we're going to talk about just one of the more common operations: parsing primitive numbers. Later in this chapter we'll delve into the java.text package, which provides full-blown parsing and formatting tools. We'll also look at the topic of internationalization to see how Java can help "localize" parsing and formatting of text, numbers, and dates for particular nationalities. Finally we'll take a detailed look at regular expressions, which are the newest and most powerful text-parsing tool Java offers. Regular expressions let you define your own patterns of arbitrary complexity, search for them, and parse them from text.
In Java, numbers and booleans are primitive types—not objects. But for each primitive type, Java also defines a primitive wrapper class. Specifically, the java.lang package includes the following classes: Byte , Short, Integer, Long, Float, Double, and Boolean. We'll talk about these in detail in Chapter 10, but we bring them up now because these classes hold static utility methods that know how to parse their respective types from strings.
For example, the Integer and Long classes provide the static methods Integer.parseInt() and Long.parseLong() that read a String and return the corresponding primitive type:
int n = Integer.parseInt( "42" ); long l = Long.parseLong( "99999999999" );
The Float and Double classes provide the static methods Float.parseFloat()and Double.parseDouble() for parsing strings into floating-point primitives:
float f = Float.parseFloat( "4.2" ); double d = Double.parseDouble( "99.99999999" );
The Boolean class deviates from this a little. Instead of having a "parse" method, you must construct a Boolean wrapper object from your string and then ask it for its value:
boolean b = new Boolean("true").booleanValue( );
The reason for this will become clearer when we examine the other uses for the primitive wrappers. Primitive wrappers support many "value" methods that allow you to convert between types.
It's easy to parse integer type numbers (byte, short, int, long) in alternate number bases. You can use the parse methods of the primitive wrapper classes, simply specifying the base as a second parameter:
long l = Long.parseLong( "CAFEBABE", 16 ); // l = 3405691582 byte b = Byte.parseByte ( "12", 8 ); // b = 10
You can also convert a long or integer value to a string value in a specified base using special static toString() methods of the Integer and Long classes:
String s = Long.toString( 3405691582L, 16 ); // s = "cafebabe"
For convenience, each class also has a static toHexString() method for working with base 16:
String s = Integer.toHexString( 255 ).toUpper( ); // s = "FF";
We'll revisit numeric parsing and formatting later in this chapter when we cover the NumberFormat class of the java.text package.
Although we can parse simple numbers in this way for simple cases, we are not taking into account the conventions used internationally. Let's pretend for a moment that we are programming Java in the rolling hills of Tuscany (some of you may not have to pretend). We would follow the local customs for representing numbers and write code like the following:
double d = Double.parseDouble("1.234,56"); // oops!
Unfortunately, this code throws a NumberFormatException, which is a runtime exception thrown whenever a number cannot be parsed. We'll see how to handle number formatting for different countries using the java.text package next.
The Java virtual machine lets us write code that executes in the same way on any Java platform. But in a global marketplace, that is only half the battle. A big question remains: will the application content and data be understandable to end users all over the world? Must users know English to use your application? The answer is that Java provides thorough support for customizing the language components of your application for most modern languages and dialects. In this section, we'll talk about the concepts of internationalization (often abbreviated "I18N") and the classes that support them.
Internationalization programming revolves around the Locale class. The class itself is very simple; it encapsulates a country code, a language code, and a rarely used variant code. Commonly used languages and countries are defined as constants in the Locale class. (It's ironic that these names are all in English.) You can retrieve the codes or readable names, as follows:
Locale l = Locale.ITALIAN; System.out.println(l.getCountry( )); // IT System.out.println(l.getDisplayCountry( )); // Italy System.out.println(l.getLanguage( )); // it System.out.println(l.getDisplayLanguage( )); // Italian
The country codes comply with ISO 3166. You will find a complete list of country codes at http://www.chemie.fu-berlin.de/diverse/doc/ISO_3166.html. The language codes comply with ISO 639. A complete list of language codes is at http://www.ics.uci.edu/pub/ietf/http/related/iso639.txt. There is no official set of variant codes; they are designated as vendor-specific or platform-specific.
You can retrieve the default Locale for your location with the static Local.getDefault() method.
Various classes throughout the Java API use a Locale to decide how to represent themselves. We ran into one earlier when talking about sorting text with the Collator class. We'll also use them later in this chapter to format numbers and currency, and again in the next chapter with the DateFormat class, which uses Locales to determine how to format and parse dates and times.
If you're writing an internationalized program, you want all the text that is displayed by your application to be in the correct language or languages. Given what you have just learned about locales, you could customize your application by testing for the current locale and printing different messages. This would quickly get cumbersome, however, because the messages for all locales would be hardcoded in your source code. ResourceBundle and its subclasses offer a cleaner, more flexible solution.
A ResourceBundle is a collection of objects your application can access by name. It acts much like the Hashtable or Map collections we'll discuss in Chapter 10, looking up objects based on Strings that serve as keys. A ResourceBundle of a given name may be defined for many different Locales. To get a particular ResourceBundle, call the factory method ResourceBundle.getBundle(), which accepts the name of the ResourceBundle and a Locale. The following example gets the ResourceBundle named "Message" for two Locales; from each bundle, it retrieves the message whose key is "HelloMessage" and prints the message:
//file: Hello.java
import java.util.*;
public class Hello {
public static void main(String[] args) {
ResourceBundle bun;
bun = ResourceBundle.getBundle("Message", Locale.ITALY);
System.out.println(bun.getString("HelloMessage"));
bun = ResourceBundle.getBundle("Message", Locale.US);
System.out.println(bun.getString("HelloMessage"));
}
}
The getBundle() method throws the runtime exception MissingResourceException if an appropriate ResourceBundle cannot be located.
ResourceBundles are defined in three ways. They can be standalone classes, in which case they are either subclasses of ListResourceBundle or direct implementations of ResourceBundle. They can also be backed by a property file, in which case they are represented at runtime by a PropertyResourceBundle object. ResourceBundle.getBundle() returns either a matching class or an instance of PropertyResourceBundle corresponding to a matching property file. The algorithm used by getBundle() is based on appending the country and language codes of the requested Locale to the name of the resource. Specifically, it searches for resources in this order:
name_language_country_variant name_language_country name_language name name_default-language_default-country_default-variant name_default-language_default-country name_default-language
In this example, when we try to get the ResourceBundle named Message, specific to Locale.ITALY, it searches for the following names (no variant codes are in the Locales we are using):
Message_it_IT Message_it Message Message_en_US Message_en
Let's define the Message_it_IT ResourceBundle now, using the lowest level mechanism, a subclass of ListResourceBundle:
import java.util.*;
public class Message_it_IT extends ListResourceBundle {
public Object[][] getContents( ) {
return contents;
}
static final Object[][] contents = {
{"HelloMessage", "Buon giorno, world!"},
{"OtherMessage", "Ciao."},
};
}
ListResourceBundle makes it easy to define a ResourceBundle class; all we have to do is override the getContents() method. This method simply returns a two-dimensional array containing the names and values of its resources. In this example, contents[1][0] is the second key (OtherMessage), and contents [1][1] is the corresponding message (Ciao.).
Now let's define a ResourceBundle for Locale.US. This time, we'll take the easy way and make a property file. Save the following data in a file called Message_en_US.properties:
HelloMessage=Hello, world! OtherMessage=Bye.
So what happens if somebody runs your program in Locale.FRANCE, and no ResourceBundle is defined for that Locale? To avoid a runtime MissingResourceException , it's a good idea to define a default ResourceBundle. In our example, you can change the name of the property file to Message.properties. That way, if a language- or country-specific ResourceBundle cannot be found, your application can still run.
The java.text package includes, among other things, a set of classes designed for generating and parsing string representations of objects. In this section, we'll talk about three classes: NumberFormat, ChoiceFormat, and MessageFormat. In Chapter 10, we'll cover the DateFormat class.
The NumberFormat class can be used to format and parse currency, percentages, or plain old numbers. NumberFormat is an abstract class, but it has several useful factory methods that produce formatters for different types of numbers. For example, to format or parse currency strings, use getCurrencyInstance():
double salary = 1234.56;
String here = // $1,234.56
NumberFormat.getCurrencyInstance( ).format(salary);
String italy = // L 1.234,56
NumberFormat.getCurrencyInstance(Locale.ITALY).format(salary);
The first statement generates an American salary, with a dollar sign, a comma to separate thousands, and a period as a decimal point. The second statement presents the same string in Italian, with a lire sign, a period to separate thousands, and a comma as a decimal point. Remember that NumberFormat worries about format only; it doesn't attempt to do currency conversion. (That would require, among other things, access to a dynamically updated table of exchange rates—a good opportunity for a JavaBean but too much to ask of a simple formatter.) We can go the other way and parse a formatted value using the parse() method, as we'll see in the next example.
Likewise, getPercentInstance() returns a formatter you can use for generating and parsing percentages. If you do not specify a Locale when calling a getInstance() method, the default Locale is used:
int progress = 44;
NumberFormat pf = NumberFormat.getPercentInstance( );
System.out.println(pf.format(progress)); // "44%"
try {
System.out.println(pf.parse("77.2%")); // "0.772"
}
catch (ParseException e) {}
And if you just want to generate and parse plain old numbers, use a NumberFormat returned by getInstance() or its equivalent, getNumberInstance():
NumberFormat guiseppe = NumberFormat.getInstance(Locale.ITALY);
// defaults to Locale.US
NumberFormat joe = NumberFormat.getInstance( );
try {
double theValue = guiseppe.parse("34.663,252").doubleValue( );
System.out.println(joe.format(theValue)); // "34,663.252"
}
catch (ParseException e) {}
We use guiseppe to parse a number in Italian format (periods separate thousands, comma is the decimal point). The return type of parse() is Number, so we use the doubleValue() method to retrieve the value of the Number as a double. Then we use joe to format the number correctly for the default (U.S.) locale.
Here's a list of the factory methods for text formatters in the java.text package. Again, we'll look at the DateFormat methods in the next chapter.
NumberFormat.getCurrencyInstance( ) NumberFormat.getCurrencyInstance(Locale inLocale) NumberFormat.getInstance( ) NumberFormat.getInstance(Locale inLocale) NumberFormat.getNumberInstance( ) NumberFormat.getNumberInstance(Locale inLocale) NumberFormat.getPercentInstance( ) NumberFormat.getPercentInstance(Locale inLocale) DateFormat.getDateInstance( ) DateFormat.getDateInstance(int style) DateFormat.getDateInstance(int style, Locale aLocale) DateFormat.getDateTimeInstance( ) DateFormat.getDateTimeInstance(int dateStyle, int timeStyle) DateFormat.getDateTimeInstance(int dateStyle, int timeStyle, Locale aLocale) DateFormat.getInstance( ) DateFormat.getTimeInstance( ) DateFormat.getTimeInstance(int style) DateFormat.getTimeInstance(int style, Locale aLocale)
Thus far we've seen how to format numbers as text. Now we'll take a look at a class, ChoiceFormat, that maps numerical ranges to text. ChoiceFormat is constructed by specifying the numerical ranges and the strings that correspond to them. One constructor accepts an array of doubles and an array of Strings, where each string corresponds to the range running from the matching number up to (but not including) the next number in the array:
double[] limits = new double [] {0, 20, 40};
String[] labels = new String [] {"young", "less young", "old"};
ChoiceFormat cf = new ChoiceFormat(limits, labels);
System.out.println(cf.format(12)); // young
System.out.println(cf.format(26)); // less young
You can specify both the limits and the labels using a special string in an alternative ChoiceFormat constructor:
ChoiceFormat cf = new ChoiceFormat("0#young|20#less young|40#old");
System.out.println(cf.format(40)); // old
System.out.println(cf.format(50)); // old
The limit and value pairs are separated by vertical bars (|); the number sign (#) separates each limit from its corresponding value.
ChoiceFormat is most useful for handling pluralization in messages, enabling you to avoid hideous constructions such as, "you have one file(s) open". You can create readable error messages by using ChoiceFormat along with the MessageFormat class. To construct a MessageFormat, pass it a pattern string. A pattern string is a lot like the string you feed to the printf() function in C/C++, although the syntax is different. Arguments are delineated by curly brackets and may include information about how they should be formatted. Each argument consists of a number, an optional type, and an optional style, as summarized in Table 9-3.
|
Type |
Styles |
|---|---|
|
Choice |
Pattern |
|
Date |
short, medium, long, full, pattern |
|
Number |
integer, percent, currency, pattern |
|
Time |
short, medium, long, full, pattern |
Let's use an example to clarify all this:
MessageFormat mf = new MessageFormat("You have {0} messages.");
Object[] arguments = {"no"};
System.out.println(mf.format(arguments)); // "You have no messages."
We start by constructing a MessageFormat object; the argument to the constructor is the pattern on which messages are based. The special incantation {0} means "use element zero from the array of arguments supplied to the format() method." When we generate a message by calling format(), we pass in values to replace the placeholders ({0}, {1}, ... ) in the template. In this case, we pass the array arguments[] to mf.format; this substitutes arguments[0], yielding the result, You have no messages.
Let's try this example again, but this time, we'll format a number and a date instead of a string argument:
MessageFormat mf = new MessageFormat(
"You have {0, number, integer} messages on {1, date, long}.");
Object[] arguments = {new Integer(93), new Date( )};
// "You have 93 messages on April 10, 2002."
System.out.println(mf.format(arguments));
In this example, we need to fill in two spaces in the template, so we need two elements in the arguments[] array. Element 0 must be a number and is formatted as an integer. Element 1 must be a Date and is printed in the long format. When we call format(), the arguments[] array supplies these two values.
This is still sloppy. What if there is only one message? To make this grammatically correct, we can embed a ChoiceFormat-style pattern string in our MessageFormat pattern string:
MessageFormat mf = new MessageFormat(
"You have {0, number, integer} message{0, choice, 0#s|1#|2#s}.");
Object[] arguments = {new Integer(1)};
// "You have 1 message."
System.out.println(mf.format(arguments));
In this case, we use element 0 of arguments[] twice: once to supply the number of messages and once to provide input to the ChoiceFormat pattern. The pattern says to add an s if argument 0 has the value zero or is two or more.
Finally, a few words on how to be clever. If you want to write international programs, you can use resource bundles to supply not only the text of messages, but the strings for your MessageFormat objects, as well. Thus you can automatically format messages that are in the appropriate language with dates and other language-dependent fields handled appropriately.
In this context, it's helpful to realize that messages don't need to read elements from the array in order. In English, you would say, "Disk C has 123 files"; in some other language, you might say, "123 files are on Disk C." You could implement both messages with the same set of arguments:
MessageFormat m1 = new MessageFormat(
"Disk {0} has {1, number, integer} files.");
MessageFormat m2 = new MessageFormat(
"{1, number, integer} files are on disk {0}.");
Object[] arguments = {"C", new Integer(123)};
In real life, the code could be even more compact; you'd use only a single MessageFormat object, initialized with a string taken from a resource bundle.
Now it's time to take a brief detour on our trip through Java and enter the land of regular expressions. A regular expression, or regex for short, describes a text pattern. Regular expressions are used with many tools—including the java.util.regex package, text editors, and many scripting languages—to provide sophisticated text-searching and powerful string-manipulation capabilities.
If you are already familiar with the concept of regular expressions and how they are used with other languages, you may wish to simply skim this section. At minimum you'll need to look at Section 9.6.2, which covers the Java package necessary to use them. On the other hand, if you've come to this point on your Java journey with a clean slate on this topic, and you're wondering exactly what regular expressions are, then pop open your favorite beverage and get ready. You are about to learn about the most powerful tool in the arsenal of text manipulation and what is, in fact, a tiny language within a language, all in the span of a few pages.
A regular expression describes a pattern in text. By pattern, we mean just about any feature you can imagine identifying in text from the literal characters alone, without actually understanding their meaning. This includes features such as words, word groupings, lines and paragraphs, punctuation, case, and more generally, strings and numbers with a specific structure to them, such as phone numbers, email addresses, and quoted phrases. With regular expressions you can search the dictionary for all the words that have the letter "q" without its pal "u" next to it, or words that start and end with the same letter. Once you have constructed a pattern, you can use simple tools to hunt for it in text or to determine if a given string matches it. A regex can also be arranged to help you dismember specific parts of the text it matched, which you could then use as elements of replacement text if you wish.
Before moving on, we should say a few words about regular expression syntax in general. At the beginning of this section, we casually mentioned that we would be discussing a new language. Regular expressions do, in fact, comprise a simple form of programming language. If you think for a moment about the examples we cited earlier, you can see that something like a language is going to be needed to describe even simple patterns—such as email addresses—that have some variation in form.
A computer science textbook would classify regular expressions at the bottom of the hierarchy of computer languages, in terms of both what they can describe and what you can do with them. They are still capable of being quite sophisticated, however. As with most programming languages, the elements of regular expressions are simple, but they can be built up in combination to arbitrary complexity. And that is where things start to get sticky.
Since regexes work on strings, it is convenient to have a very compact notation that can be easily wedged between characters. But compact notation can be very cryptic, and experience shows that it is much easier to write a complex statement than to read it again later. Such is the curse of the regular expression. You may find that in a moment of late-night, caffeine-fueled inspiration, you can write a single glorious pattern to simplify the rest of your program down to one line. When you return to read that line the next day, however, it may look like just so much Egyptian hieroglyphics to you. Simpler is generally better. If you can break your problem down and do it more clearly in several steps, maybe you should.
Now that you're properly warned, we have to throw one more thing at you before we build you back up. Not only can the regex notation get a little hairy, but it is also somewhat ambiguous with ordinary Java strings. An important part of the notation is the escaped character, a character with a backslash in front of it. For example, the escaped d character, \d, is shorthand that matches any single digit character (0-9). However, you cannot simply write "\d" as part of a Java string, because Java uses the backslash for its own special characters and to specify Unicode character sequences. Fortunately, Java gives us a replacement: an escaped backslash, which is two backslashes (\\), means a literal backslash. The rule is that when you want a backslash to appear in your regex, you must escape it with an extra one:
"\\d" // Java string that yields backslash "d"
And just to make things crazier, because regex notation itself uses backslash to denote special characters, it must provide the same "escape hatch" as well—allowing you to double up backslashes if you want a literal backslash. If you want to specify a regular expression that includes a single literal backslash, it looks like this:
"\\\\" // Java string yields two backslashes; regex yields one
Most of the "magic" operator characters you read about in this section operate on the character that precedes them, so these also must be escaped if you want their literal meaning. This includes such characters as .,*,+, braces {}, and parentheses ().
If you need to create part of an expression that has several literal characters in it, you might be able to use the special delimiters \Q and \E to help you. Any text appearing between \Q and \E is automatically escaped. (Note that you still need the Java String escapes—double backslashes for backslash, but not quadruple).
Beyond that, my only suggestion to help maintain your sanity when working with these examples is to keep two copies—a comment line showing the naked regular expression and the real Java string, where you must double up all backslashes.
Now let's dive into the actual regex syntax. The simplest form of a regular expression is just some plain, literal text, which means match exactly that text. This can be a single character or more. For example, in the following string, the pattern s can match the character s in the words rose and is:
"A rose is $1.99."
The pattern rose can match only the literal word rose. But this isn't very interesting. Let's crank things up a notch by introducing some special characters and the notion of character "classes."
The special character dot (.) matches any single character. The pattern .ose matches rose, nose, ose (space followed by ose) or any other character followed by the sequence ose. Two dots match any two characters, and so on. The dot operator is nondiscriminating. It normally stops only for an end-of-line character (and, optionally, you can tell it not to; we discuss that later).
We can consider "." to represent the group or class of all characters. And regexes define more interesting character classes as well.
The special character \s matches a literal-space character or one of the following characters: \t (tab), \r (carriage return), \n (newline), \f (formfeed), and backspace. The corresponding special character \S does the inverse, matching any character except whitespace.
\d matches any of the digits 0-9. \D does the inverse, matching all characters but digits.
\w matches a "word" character, including upper- and lowercase letters A-Z, a-z, the digits 0-9, and the underscore character ( _ ). \W matches everything except those characters.
You can define your own character classes using the notation [...]. For example, the following class matches any of the characters a, b, c, x, y, or z:
[abcxyz]
The special x-y range notation can be used as shorthand for the alphabetic characters. The following example defines a character class containing all upper- and lowercase letters:
[A-Za-z]
Placing a caret (^) as the first character inside the brackets inverts the character class. For example:
[^A-F] // G, H, I, ..., a, b, c, ... etc.
matches any character except uppercase A through F.
Nesting character classes simply adds them:
[A-F[G-Z]] // A-Z
The && logical AND notation can be used to take the intersection (characters in common):
[a-p&&[l-z]] // l, m, n, o, p [A-Z&&[^P]] // A through Z except P
The pattern "[Aa] rose" (including an upper- or lowercase A) matches three times in the following phrase:
"A rose is a rose is a rose"
Position characters allow you to designate the relative location of a match. The most important are ^ and $, which match the beginning and end of a line, respectively:
^[Aa] rose // matches "A rose" at the beginning of line [Aa] rose$ // matches "a rose" at end of line
Actually, by default, ^ and $ match the beginning and end of "input," which is often a line. If you are working with multiple lines of text and wish to match the beginnings and endings of lines within a single large string, you can turn on "multiline" mode—see the later section Section 9.6.1.11.
The position markers \b and \B match a word boundary or nonword boundary, respectively. For example, the following pattern matches rose and rosemary, but not primrose:
\brose
Simply matching fixed character patterns would not get us very far. Next we look at operators that count the number of occurrences of a character (or more generally, of a pattern, as we'll see later).
Placing an asterisk after a character or character class means "allow any number of that type of character"—in other words, zero or more. For example, the following pattern matches a digit with any number of leading zeros (possibly none):
0*\d // match a digit with any number of leading zeros
The plus sign (+) means "one or more" iterations and is equivalent to XX* (pattern followed by pattern asterisk). For example, the following pattern matches a multiple-digit number with leading zeros:
0*\d+ // match a number (one or more digits) with leading zeros
It may seem redundant to match the zeros at the beginning of expression because zero is, of course, a digit and is matched by the \d+ portion of the expression anyway. However, we'll show later how you can pick apart the string using a regex and get at just the pieces you want. For example, in this case, you might want to strip off the leading zeros and keep just the digits.
The question mark operator (?) allows exactly zero or one iteration. For example, the following pattern matches a credit-card expiration date, which may or may not have a slash in the middle:
\d\d/?\d\d // match four digits with an optional slash in the middle
The {x,y} curly-brace range operator is the most general iteration operator. It specifies a precise range to match. A range takes two arguments: a lower bound and an upper bound, separated by a comma. This regex matches any word with five to seven characters, inclusive:
\b\w{5,7}\b // match words with at least 5 and at most 7 letters
If you omit the upper bound, simply leaving a dangling comma in the range, the upper bound becomes infinite. This is a way to specify a minimum of occurrences with no maximum.
Just as in logical or mathematical operations, parentheses can be used in regular expressions to make subexpressions or to put boundaries on parts of expressions. This power lets us extend the operators we've talked about to work not only on characters, but on also words or other regular expressions. For example:
(yada)+
Here we are applying the + (one or more) operator to the whole pattern yada, not just one character. It matches yada, yadayada, yadayadayada, and so on.
Using grouping, we can start building more complex expressions. For example, while many email addresses have a three-part structure (e.g., [email protected]), the domain name portion can, in actuality, contain an arbitrary number of dot-separated components. To handle this properly, we can use an expression like this one:
\w+@\w+(\.\w)+ // Match an email address
This expression matches a word, followed by an @ symbol, followed by another word and then one or more literal dot-separated words, e.g., [email protected], [email protected], or [email protected].
In addition to basic grouping of operations, parentheses have an important, additional role: the text matched by each parenthesized subexpression can be separately retrieved. That is, you can isolate the text that matched each subexpression. There is then a special syntax for referring to each capture group within the regular expression by number. This important feature has two uses.
First, you can construct a regular expression that refers to the text it has already matched and uses this text as a parameter for further matching. This allows you to express some very powerful things. For example, we can now show the dictionary example we mentioned in the introduction. Let's find all the words that start and end with the same letter:
\b(\w)\w*\1\b // match words beginning and ending with the same letter
See the 1 in this expression? It's a reference to the first capture group in the expression, \w. References to capture groups take the form \n where n is the number of the capture group, counting from left to right. In this example, the first capture group matches a word character on a word boundary. Then we allow any number of word characters up to the special reference \1 (also followed by a word boundary). The \1 means "the value matched in capture group one." Since these characters must be the same, this regex matches words that start and end with the same character.
The second use of capture groups is in referring to the matched portions of text while constructing replacement text. We'll show you how to do that a bit later when we talk about the Regular Expression API.
Capture groups can contain more than one character, of course, and you can have any number of groups. You can even nest capture groups. Next, we discuss exactly how they are numbered.
Capture groups are numbered, starting at 1, and moving from left to right, by counting the number of open parentheses it takes to reach them. The special group number 0 always refers to the entire expression match. For example, consider the following string:
one ((two) (three (four)))
This string creates the following matches:
Group 0: one two three four Group 1: two three four Group 2: two Group 3: three four Group 4: four
Before going on, we should note one more thing. So far in this section we've glossed over the fact that parentheses are doing double duty: creating logical groupings for operations and defining capture groups. What if the two roles conflict? Suppose we have a complex regex that uses parentheses to group subexpressions and to create capture groups? In that case, you can use a special noncapturing group operator (?:) to do logical grouping instead of using parentheses. You probably won't need to do this often, but it's good to know.
The vertical bar (|) operator denotes the logical OR operation, also called alternation or choice. The | operator does not operate on individual characters but instead applies to everything on either side of it. It splits the expression in two unless constrained by parentheses grouping. For example, a slightly naïve approach to parsing dates might be the following:
\w+, \w+ \d+ \d+|\d\d/\d\d/\d\d // pattern 1 or pattern 2
In this expression, the left side matches patterns such as Fri, Oct 12 2001, and the right matches 10/12/2001.
The following regex might be used to match email addresses with one of three domains (net, edu, and gov):
\w+@[\w\.]*\.(net|edu|gov) // email address ending in .net, .edu, or .gov
There are several special options that affect the way the regex engine performs its matching. These options can be applied in two ways:
You can pass in one or more flags during the Pattern.compile() step (discussed later in this chapter)
You can include a special block of code in your regex
We show the latter approach. To do this, include one or more flags in a special block (?x) where x is the flag for the option we want to turn on. Generally, you do this at the beginning of the regex. You can also turn off flags by adding a minus sign (?-x), which allows you to apply flags to select parts of your pattern.
The following flags are available:
The (?i) flag tells the regex engine to ignore case while matching, for example:
(?i)yahoo // match Yahoo, yahoo, yahOO, etc.
The (?s) flag turns on "dot all" mode, allowing the dot character to match anything, including end-of-line characters. It is useful if you are matching patterns that span multiple lines. The s stands for "single line mode," a somewhat confusing name derived from Perl.
By default, ^ and $ don't really match the beginning and ending of lines (as defined by carriage return or newline combinations); they instead match the beginning or ending of the entire input text. Turning on multiline mode with (?m) causes them to match the beginning and ending of every line as well as the beginning and end of input. Specifically, this means the spot before the first character, the spot after the last character, and the spots just after and just before line terminators inside the string.
The (?d) flag changes the definition of the line terminator for the ^, $, and . special characters to Unix-style newline only (\n). By default, carriage return newline (\r\n) is also allowed.
We've seen hints that regular expressions are capable of sorting out some complex patterns. But there are cases where what is matched is ambiguous (at least to you, though not in fact to the regex engine). Probably the most important example has to do with the number of characters the iterator operators consume before stopping. The .* operation best illustrates this. Consider the following string:
"Now is the time for <bold>action</bold>, not words."
Suppose we want to search for all the HTML-style tags (the parts between the < and > characters), perhaps because we want to remove them.
We might naïvely start with this regex:
</?.*> // match <, optional /, and then anything up to >
We then get the following match, which is much too long:
<bold>action</bold>
The problem is that the .* operation, like all the iteration operators, is by default "greedy," meaning that it consumes absolutely everything it can, up until the last match for the terminating character (in this case >) in the file or line.
There are solutions for this problem. The first is to "say what it is," that is, to be more specific about what is allowed between the braces. The content of an HTML tag cannot actually include anything; for example, it cannot include a closing bracket (>). So we could rewrite our expression as:
</?\w*> // match <, optional /, any number of word characters, then >
But suppose the content is not so easy to describe. For example, we might be looking for quoted strings in text, which could include just about any text. In that case we can use a second approach and "say what it is not." We can invert our logic from the previous example and specify that anything except a closing bracket is allowed inside the brackets:
</?[^>]*>
This is probably the most efficient way to tell the regex engine what to do. It then knows exactly what to look for to stop reading. This approach has limitations, however. It is not obvious how to do this if the delimiter is more complex than a single character. It is also not very elegant.
Finally, we come to our general solution: the use of "reluctant" operators. For each of the iteration operators, there is an alternative, nongreedy form that consumes as few characters as possible, while still trying to get a match with what comes after it. This is exactly what we needed in our previous example.
Reluctant operators take the form of the standard operator with a "?" appended. (Yes, we know that's confusing.) We can now write our regex as:
</?.*?> // match <, optional /, minimum number of any chars, then >
Here we have appended ? to .* to cause .* to match as few characters as possible while still making the final match of >. The same technique (appending the ?) works with all the iteration operators, as in the two following examples:
.+? // one or more, nongreedy
.{x,y}? // between x and y, nongreedy
In order to understand our next topic, let's return for a moment to the position marking characters (^, $, \b, and \B) that we discussed earlier. Think about what exactly these special markers do for us. We say, for example, that the \b marker matches a word boundary. But the word "match" here may be a bit too strong. In reality, it "requires" a word boundary to appear at the specified point in the regex. Suppose we didn't have \b; how could we construct it? Well, we could try constructing a regex that matches the word boundary. It might seem easy, given the word and nonword character classes (\w and \W):
\w\W|\W\w // match the start or end of a word
But now what? We could try inserting that pattern into our regular expressions wherever we would have used \b, but it's not really the same. Now we're actually matching those characters not just requiring them. This regular expression matches the two characters comprising the word boundary in addition to whatever else matches afterwards, whereas the \b operator simply requires the word boundary but doesn't match any text. The distinction is that \b isn't a matching pattern but a lookahead. A lookahead is a pattern that is required to match next in the string, but which is not consumed by the regex engine. When a lookahead pattern succeeds, the pattern moves on, and the characters are left in the stream for the next part to use. If the lookahead fails, the match fails (or it backtracks and tries a different approach).
We can make our own lookaheads with the lookahead operator (?=). For example, to match the letter X at the end of a word we could use:
(?=\w\W)X // Find X at the end of a word
Here the regex engine requires the \W\w pattern to match but not consume the characters, leaving them for the next part of the pattern. This effectively allows us to write overlapping patterns (like the previous example). For instance, we can match the word "Pat" only when it's part of the word "Patrick," like so:
(?=Patrick)Pat // Find Pat only in Patrick
Another operator (?!)—the negative lookahead—requires that the pattern not match. We can find all the occurrences of Pat not inside of a Patrick with this:
(?!Patrick)Pat // Find Pat never in Patrick
It's worth noting that we could have written all of these examples in other ways, by simply matching a larger amount of text. For instance, in the first example we could have matched the whole word "Patrick". But that is not as precise, and if we wanted to use capture groups to pull out the matched text or parts of it later, we'd have to play games to get what we want. For example, suppose we wanted to substitute something for Pat (say, change the font). We'd have to use an extra capture group and replace the text with itself. Using lookaheads is much more elegant.
In addition to looking ahead in the stream, we can use the (?<=) and (?<!) lookbehind operators to look backwards in the stream. For example, we can find my last name, but only when it refers to me:
(?<=Pat )Niemeyer // Niemeyer, only when preceded by Pat
Or we can find the string "bean" when it is not part of the phrase "Java bean":
(?<!Java *)bean // The word bean, not preceded by Java
In these cases, the lookbehind and the matched text didn't overlap because the lookbehind was before the matched text. But you can place a lookahead or lookbehind at either point—before or after the match; for example, we could also match Pat Niemeyer like this:
Niemeyer(?<=Pat Niemeyer)
Now that we've covered the theory of how to construct regular expressions, the hard part is over. All that's left is to investigate the Java API for applying regexes: searching for them in strings, retrieving captured text, and replacing matches with substitution text.
As we've said, the regex patterns that we write as strings are, in actuality, little programs describing how to match text. At runtime, the Java regex package compiles these little programs into a form that it can execute against some target text. Several simple convenience methods accept strings directly to use as patterns. More generally however, Java allows you to explicitly compile your pattern and encapsulate it in an instance of a Pattern object. This is the most efficient way to handle patterns that are used more than once, because it eliminates needlessly recompiling the string. To compile a pattern, we use the static method Pattern.compile():
Pattern urlPattern = Pattern.compile("\\w+://[\\w/]*");
Once you have a Pattern, you can ask it to create a Matcher object, which associates the pattern with a target string:
Matcher matcher = urlPattern.matcher( myText );
The matcher is what actually executes the matches. We'll talk about it next. But before we do, we'll just mention one convenience method of Pattern. The static method Pattern.matches() simply takes two strings—a regex and a target string—and determines if the target matches the regex. This is very convenient if you just want to do a quick test once in your application. For example:
Boolean match = Pattern.matches( "\\d+\\.\\d+f?", myText );
The previous line of code can test if the string myText contains a Java-style floating-point number such as "42.0f". Note that the string must match completely, to the end, to be considered a match.
A Matcher associates a pattern with a string and provides tools for testing, finding, and iterating over matches of the pattern against it. The Matcher is "stateful." For example, the find() method tries to find the next match each time it is called. But you can clear the Matcher and start over by calling its reset() method.
If you're just interested in "one big match"—that is, you're expecting your string to either match the pattern or not—you can use matches() or lookingAt(). These correspond roughly to the methods equals() and startsWith() of the String class. The matches() method asks if the string matches the pattern in its entirety (with no string characters left over) and returns true or false. The lookingAt() method does the same, except that it asks only whether the string starts with the pattern and doesn't care if the pattern uses up all the string's characters.
More generally, you'll want to be able to search through the string and find one or more matches. To do this, you can use the find() method. Each call to find() returns true or false for the next match of the pattern and internally notes the position of the matching text. You can get the starting and ending character positions with the Matcher start() and end() methods, or you can simply retrieve the matched text with the group() method. For example:
import java.util.regex.*;
String text="A horse is a horse, of course of course...";
String pattern="horse|course";
Matcher matcher = Pattern.compile( pattern ).matcher( text );
while ( matcher.find( ) )
System.out.println(
"Matched: '"+matcher.group()+"' at position "+matcher.start( ) );
The previous snippet prints the starting location of the words "horse" and "course" (four in all):
Matched: 'horse' at position 2 Matched: 'horse' at position 13 Matched: 'course' at position 23 Matched: 'course' at position 33
The method to retrieve the matched text is called group() because it refers to capture group zero (the entire match). You can also retrieve the text of other numbered capture groups by giving the group() method an integer argument. You can determine how many capture groups you have with the groupCount() method:
for (int i=1; i < matcher.groupCount( ); i++) System.out.println( matcher.group(i) );
A very common need is to parse a string into a bunch of fields based on some delimiter, such as a comma. It's such a common problem that in Java 1.4, a method was added to the String class for doing just this. The static method String.split() accepts a regular expression and returns an array of substrings broken around that pattern. For example:
String text = "Foo, bar , blah"; String [] fields = String.split( "\s*,\s*", text)
yields a String array containing Foo, bar, and blah. You can control the maximum number of matches and also whether you get "empty" strings (for text that might have appeared between two adjacent delimiters) using an optional limit field.
If you are going to use an operation like this more than a few times in your code, you should probably compile the pattern and use its split() method, which is identical to the version in String. The String.split() method is equivalent to:
Pattern.compile(pattern).split(string);
A common reason that you'll find yourself searching for a pattern in a string is to change it to something else. The regex package not only makes it easy to do this but also provides a simple notation to help you construct replacement text using bits of the matched text.
The most convenient form of this API is Matcher's replaceAll() method, which substitutes a replacement string for each occurrence of the pattern and returns the result. For example:
String text = "Richard Nixon's social security number is: 567-68-0515.";
Matcher matcher =
Pattern.compile("\\d\\d\\d-\\d\\d\-\\d\\d\\d\\d").matcher( text );
String output = matcher.replaceAll("XXX-XX-XXXX");
This code replaces all occurrences of U.S. government Social Security numbers with "XXX-XX-XXXX" (perhaps for privacy considerations).
Literal substitution is nice, but we can make this even more powerful by using capture groups in our substitution pattern. To do this, we use the simple convention of referring to numbered capture groups with the notation $n, where n is the group number. For example, suppose we wanted to show just a little of the Social Security number in the above example, so that the user would know if we were talking about him. We could modify our regex to catch, for example, the last four digits like so:
\d\d\d-\d\d-(\d\d\d\d)
We can then use that in the substitution text:
String output = matcher.replaceAll("XXX-XX-$1");
The replaceAll() method is useful, but you may want more control over each substitution. You may want to change each match to something different or base the change on the match in some programmatic way.
To do this, you can use the Matcher appendReplacement() and appendTail() methods. These methods can be used in conjunction with the find() method as you iterate through matches to build a replacement string. appendReplacement() and appendTail() operate on a StringBuffer that you supply. The appendReplacement() method builds a replacement string by keeping track of where you are in the text and appending all nonmatched text to the buffer for you as well as the substitute text that you supply. Each call to find() appends the intervening text from the last call, followed by your replacement, then skips over all the matched characters to prepare for the next one. Finally, when you have reached the last match, you should call appendTail(), which appends any remaining text after the last match. We'll show an example of this next, as we build a simple "template engine."
Now let's tie together what we've discussed in a nifty example. A common problem that comes up in Java applications is working with bulky, multiline text. In general, you don't want to store text messages in your application code, because it makes them difficult to edit or internationalize. But when you move them to external files or resources, you need a way for your application to plug in information at runtime. The best example of this is in Java servlets; a generated HTML page is often 99% static text with only a few "variable" pieces plugged in. Technologies such as JSP and XSL were developed to address this. But these are big tools, and we have a simple problem. So let's create a simple solution—a template engine.
Our template engine reads text containing special template tags and substitutes values that we provide it. And since generating HTML or XML is one of the most important applications of this, we'll be friendly to those formats by making our tags conform to the style of an XML comment. Specifically, our engine searches the text for tags that look like this:
<!--TEMPLATE:name This is the template for the user name -->
XML style comments start with <!-- and can contain anything up to a closing -->. We'll add the convention of requiring a TEMPLATE:name field to specify the name of the value we want to use. But aside from that, we'll still allow any descriptive text the user wants to include. To be friendly (and consistent), we'll allow any amount of whitespace to appear in the tags, including multiline text in the comments. We'll also ignore the text case of the "TEMPLATE" identifier, just in case. Now, we could do this all with low level String commands, looping over whitespace and taking substrings a lot. But using the power of regexes, we can do it much more cleanly and with only about seven lines of relevant code. (We've rounded out the example with a few more to make it more useful).
import java.util.*;
import java.util.regex.*;
public class Template
{
Properties values = new Properties( );
Pattern templateComment =
Pattern.compile("(?si)<!--\\s*TEMPLATE:(\\w+).*?-->");
public void set( String name, String value ) {
values.setProperty( name, value );
}
public String fillIn( String text ) {
Matcher matcher = templateComment.matcher( text );
StringBuffer buffer = new StringBuffer( );
while( matcher.find( ) ) {
String name = matcher.group(1);
String value = values.getProperty( name );
matcher.appendReplacement( buffer, value );
}
matcher.appendTail( buffer );
return buffer.toString( );
}
}
You'd use the Template class like this:
String input = "<!-- TEMPLATE:name --> lives at "
+"<!-- TEMPLATE:address -->";
Template template = new Template( );
template.set("name", "Bob");
template.set("address", "1234 Main St.");
String output = template.fillIn( input );
In this code, input is a string containing tags for name and address. The set() method provides the values for those tags.
Let's start by picking apart the regex, templatePattern, in the example:
(?si)<!--\s*TEMPLATE:(\w+).*?-->
It looks scary, but it's actually very simple. Just start reading from left to right. First, we have the special flags declaration (?si) telling the regex engine that it should be in single-line mode, with .* matching all characters including newlines (s), and ignoring case (i). Next, there is the literal <!-- followed by any amount of whitespace (\s) and the TEMPLATE: identifier. After the colon, we have a capture group (\w+), which reads our name identifier and saves it for us to retrieve later. We allow anything (.*) up to the -->, being careful to specify that .* should be nongreedy (.*?). We don't want .* to consume other opening and closing comment tags all the way to the last one but instead to find the smallest match (one tag).
Our fillIn() method does the work, accepting a template string, searching it, and "replacing" the tag values with the values from set(), which we have stored in a Properties table. Each time fillIn() is called, it creates a Matcher to wrap the input string and get ready to apply the pattern. It then creates a temporary StringBuffer to hold the output and loops, using the Matcher find() method to get each tag. For each match, it retrieves the value of the capture group (group one) that holds the tag name. It looks up the corresponding value and replaces the tag with this value in the output string buffer using the appendReplacement() method. (Remember that appendReplacement() fills in the intervening text on each call, so we don't have to.) All that remains is to call appendTail() at the end to get the remaining text after the last match and return the string value. That's it!
Regular expressions aren't new, but they are new to Java (at least as a standard). We have shown you some of the power provided by these tools and (we hope) whetted your appetite for more. Regexes allow you to work in ways you may not have considered before. Especially now, when the software world is focused on textual representations of almost everything—from data to user interfaces—via XML and HTML, having powerful text-manipulation tools is fundamental. Just remember to keep those regexes simple so you can reuse them again and again. .
[1] In Windows, the default encoding is CP1252; in Solaris, it's ISO8859_1.
[2] Locales help you deal with issues relevant to particular languages and cultures; we'll talk about them in the later section Section 9.4.
| CONTENTS |